
- 16 février 2022
LES DONNÉES GÉOGRAPHIQUES AUJOURD’HUI
Aujourd’hui l’exploitation des données cartographiques prend une part de plus en plus importante dans le monde de l’intelligence artificielle, du fait de la mise à disposition très large de ces données (via OpenStreetMap ou encore des photos satellite) et l’avènement des technologies de reconnaissance d’images.
L’exploitation de données cartographiques pour trouver des zones similaires trouve des applications dans de nombreux domaines :
- L’information géographique en général,
- L’opération et le maintien d’un réseau national comme la distribution d’électricité ou les télécom,
- L’aménagement du territoire,
- L’analyse immobilière,
- Les études d’implantations commerciales ou industrielles,
- La prévention des risques naturels.
D’autre part, la récolte de ce type de données peut s’avérer chronophage et demander un long temps de préparation (d’autant plus si elles doivent être labellisées) avant qu’elles puissent être utilisables dans des modèles de machine learning.
Récemment, par ailleurs, les technologies dites d’auto-apprentissage (self learning) ont permis des avancées considérables dans le domaine de la reconnaissance d’images, en s’extrayant de la nécessité de labelliser les images une-à-une.
LES QUESTIONS À SE POSER
Nous nous sommes donc posé les questions suivantes :
Est-il possible pour un algorithme de caractériser de manière pertinente un environnement géographique de manière synthétique (résumée), c’est-à-dire en une dizaine de critères maximum ?
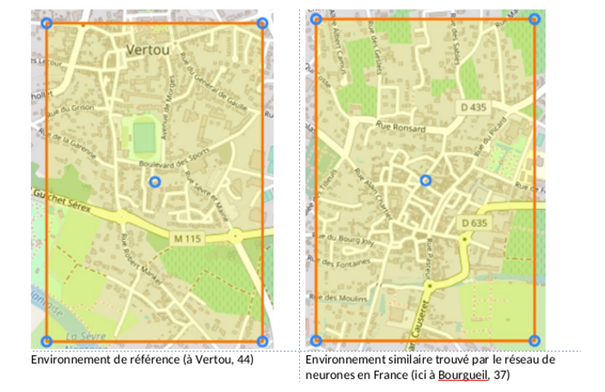
Ici par exemple on a, en entrée, une localisation à Vertou, et une localisation de sortie à Bourgueil. On voit très clairement que, dans ce cas, les environnements sont très similaires (espaces verts, axe routier principal, cours d’eau à proximité…)
Est-ce que le self-learning permet d’aider à cette tâche ?
L’objectif ultime étant, de donner en entrée à l’algorithme, une localisation puis qu’il nous retourne en sortie une localisation avec un environnement
similaire.
LE PROCESSUS DE GÉNÉRATION DE TUILES
Qu’est-ce qu’une tuile et comment la génère-t-on ?
La première étape est toujours celle de la récupération de données et pour cela nous nous sommes basés sur une ressource principale : Open Street Map (OSM).
Il s’agit d’un projet collaboratif de cartographie dont les données sont librement accessibles et exploitables. OSM dispose de pratiquement toutes les informations nécessaires pour caractériser un environnement : routes, bâtiments, cours d’eau, espaces verts etc. Les bases de données sont disponibles pour tous, permettant de les importer et d’effectuer des requêtes dessus librement.
OSM est donc notre principale ressource pour extraire de l’informations à propos de l’environnement de localisations.
Puisque nous allons créer un réseau de neurones capable de caractériser ces données extraites d’Open Street Map, nous devons générer plusieurs dizaines de milliers de localisations en vue de l’entraînement. Il faut également penser à générer ces localisations réparties de manière uniforme sur tout le territoire français : plus la diversité d’environnement est grande, meilleure sera la caractérisation faite par l’algorithme.
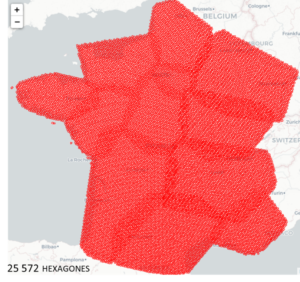
Pour cela, nous utilisons la librairie h3, développée par Uber, qui permet de carroyer le globe sous formes d’hexagones à plusieurs niveaux de granularité. Pour recouvrir la France nous disposons de 25572 hexagones puis nous générons trois localisations à l’intérieur de chaque hexagone. Nous aboutissons ainsi à plus de 75 000 points uniformément répartis sur le territoire français.
Une fois les localisations générées, il faut récupérer les données correspondants à chacun de ces endroits (ou environnements, voir figure plus bas). L’environnement d’une position géographique est appelé une “tuile”. Nous avons fait le choix ici de partir sur une surface de tuile d’environ 4km² avec la localisation en point central. Cela signifie que l’algorithme « verra » uniquement l’environnement proche à 4 km à la ronde dans sa caractérisation.
Voici par exemple à quoi pourrait ressembler une tuile OSM pour un emplacement se situant dans le centre d’Angers :
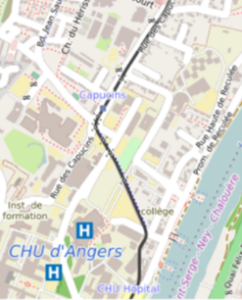
La tuile intègre ici en fait plusieurs couches OSM, que nous avons choisies : les cours d’eau, la voirie, les transports en commun, les hôpitaux, etc.
Ce choix dépend du cas d’usage et de ce qui doit être caractérisé dans l’environnement d’une position géographique.
Comment indiquer à l’algorithme que deux environnements se ressemblent ?
On va considérer ici que deux environnements se ressemblent lorsque, par exemple, ils sont tous deux une zone urbaine dense, ou bien s’ils sont tous deux des zones rurales avec un cours d’eau à proximité.
La notion de base pour apprendre à la machine cette notion de ressemblance va être le triplet. Celui-ci, comme son nom l’indique, est composé de trois éléments :
- L’élément de base est appelé ancre de référence il s’agit de l’image correspondant à une couche, par exemple les bâtiments pour la localisation : 47°29’14.5″N 0°33’30.0″W
- Le deuxième élément est appelé ancre positive, on parle ici d’une image qui est vraiment similaire à celle de référence. Par exemple si l’ancre de référence est une image correspondant à des bâtiment dans un centre-ville dense, alors l’ancre positive sera également une image de bâtiment dans un centre-ville dense.
- Le dernier élément est l’ancre négative, à l’inverse de l’ancre positive c’est une image qui n’est pas du tout similaire à celle de référence. Dans notre exemple il s’agit d’une image ou la concentration de bâtiment n’est pas dense du tout.
Voici un exemple de Triplet pour un projet de reconnaissance faciale mené par Google :
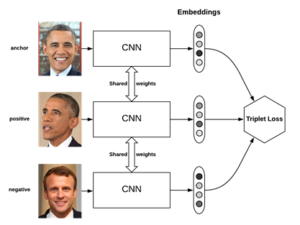
Les images sont passées en noir et blanc pour que l’algorithme puisse mieux distinguer ce qui caractérise un environnement.
Voici donc à quoi ressemblerait un triplet pour une localisation en centre-ville et pour la couche des bâtiments.
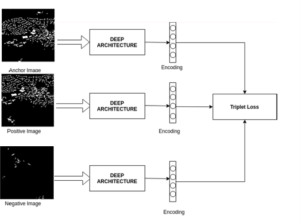
Pour chaque localisation et chaque couche, nous indiquons au réseau de neurones que, dans son apprentissage, il doit penser à caractériser l’ancre de référence et l’ancre positive de la même manière. De même il doit comprendre quelles sont les différences entre l’ancre de référence et celle qui est négative pour ne pas les caractériser de la même manière.
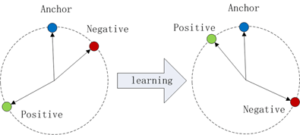
Cela se traduit par le calcul d’une fonction de perte qui indique si le réseau de neurones apprend correctement. La métrique associée à ce calcul s’appelle la « loss value ». Elle cherche à vérifier que l’écart entre l’ancre et l’ancre positive soit plus grand que celui entre l’ancre et l’ancre négative, soit :
On cherche à ce qu’elle se rapproche au plus possible de 0, cela signifiera que l’algorithme est bon et qu’il converge. Ici l’élément alpha cherche à empêcher le cas où tous les x sont égaux.
L’ENTRAÎNEMENT DU RÉSEAU DE NEURONES
Il est alors possible de mettre en place un réseau de neurones à convolutions, qui à partir des milliers de triplets générés, sera capable de caractériser un environnement en seulement 8 informations.
Lorsqu’on entraîne un réseau de neurones on peut choisir la taille du vecteur d’embeddings qui est retourné en sortie. Dans notre cas, nous avons défini, de manière empirique, que 8 variables était le nombre optimal pour décrire un environnement.
On construit alors un réseau de neurones qui va effectuer 50 entraînements (epochs). Pour chaque entraînement on divise nos localisations en 70% pour l’entraînement et 30% pour le test. On peut donc ainsi calculer la valeur de la fonction de perte pour chaque échantillon, le but étant de vérifier qu’on ne sur-apprends pas mais aussi que l’algorithme converge bien.
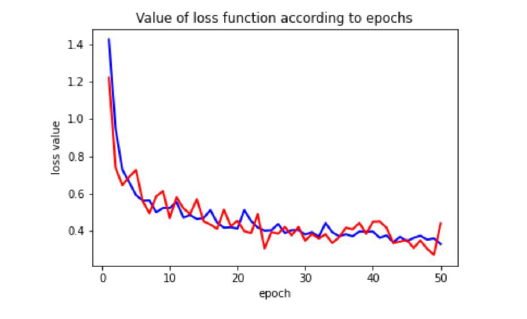
Ici on a en rouge la courbe d’entraînement et en bleu celle de validation. Ce qui est positif c’est qu’au fur et à mesure des epochs les valeurs de la loss value diminuent puis se stabilisent, cela indique que l’algorithme semble bien converger. Autre point positif, l’algorithme ne sur-apprends pas.
L’ENTRAÎNEMENT DU RÉSEAU DE NEURONES
Pour illustrer les résultats de l’entraînement et vérifier que notre algorithme fonctionne bien on va partir d’un point de référence. Considérons qu’une personne possède une maison à Vertou et souhaite déménager pour X raisons, le bien pour lequel cette personne déménage doit un environnement le plus similaire possible à la maison de Vertou.
En parallèle, nous avons généré plus de 150 000 tuiles sur la région des Pays de La Loire. L’objectif est que l’algorithme puisse trouver les environnement les plus ressemblants à différentes échelles de distance : 10, 30, 50, 100 et 200km.
Pour chaque cas on regarde la valeur de l’indice de dissimilarité qui correspond à la distance entre les vecteurs caractérisant deux tuiles, plus la distance est faible plus deux tuiles seront caractérisée de la même façon.
Cela donne :
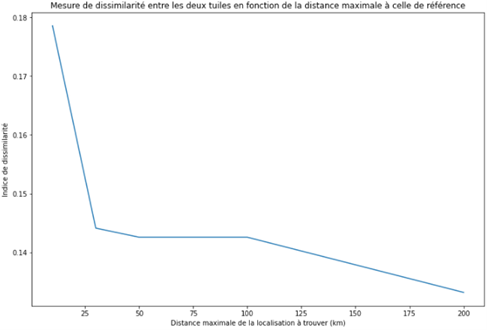
Naturellement, plus on s’éloigne de notre maison de référence, plus le nombre de tuiles à comparer est riches en diversité d’environnements. Cela se traduit par la forte baisse de l’indice de dissimilarité qui nous montre que plus on s’éloigne de notre maison plus on réussira à trouver un environnement similaire.
Pour rappel, voilà à quoi ressemble la tuile pour la maison de Vertou :
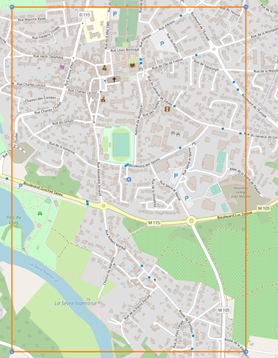
On examine alors la tuile retourné qui se situe à moins de 10km de celle de base :
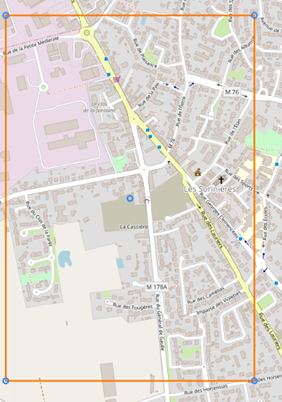
On remarque quelques points communs avec la tuile de Vertou et notamment l’axe routier principal ainsi que la présence d’une église et de quelques petits espaces verts. Cependant certains éléments de l’environnement de Vertou sont encore manquants.
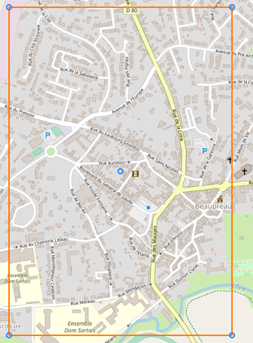
Si on s’éloigne et qu’on s’intéresse à la tuile retournée dans un rayon de 50km on retrouve les éléments intéressants de notre environnement de base, et notamment ici on voit un cours d’eau se rajouter. On note également la présence d’un collège et d’un lycée, point commun avec la tuile de Vertou. Enfin, niveau culturel on note également la présence d’un cinéma dans les deux tuiles.
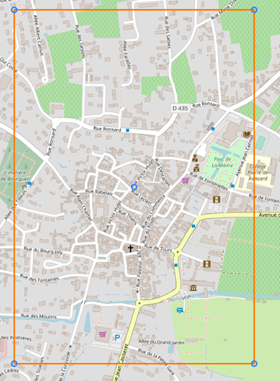
Finalement la tuile située à Bourgueil est l’environnement avec l’indice de similarité le plus faible dans un rayon de 200km. L’environnement présente encore plus de points communs. On retrouve bien évidemment : l’axe routier principal, les espaces verts, les cours d’eau, le cinéma et l’église, le collège. Cependant on retrouve également un parc de loisir, et un centre-ville de taille similaire avec la même densité de bâtiment.
CONCLUSION
Avec tout ce travail nous savons à présent que nous sommes capables de récupérer de manière automatique des données géographiques lié à une localisation. En effet le processus de génération de tuile permet, pour n’importe quelle localisation, de récupérer les données souhaitées concernant son environnement. Cette procédure à plusieurs objectifs, le premier est exploratoire puisqu’on comprend vite, à partir des images des tuiles, les éléments importants dans l’environnement de notre localisation. Le deuxième est que ces tuiles sont le point de départ de l’étape de de caractérisation automatique d’environnement.
Nous avons également vu qu’un algorithme est capable d’apprendre à caractériser un environnement de manière synthétique sous forme d’un vecteur de réels. En se basant sur des architectures spécifiques telles que la Triplet Loss on arrive à renforcer l’apprentissage et avoir des résultats réellement satisfaisant, puisqu’on sait que le vecteur de réel retourné par l’algorithme est réellement en mesure d’apporter de l’information sur l’environnement d’une localisation.
On peut alors à présent effectuer un simple calcul de distance pour trouver des localisations ayant des environnements similaires comme pour notre problème avec la maison de Vertou. Il est donc possible pour un utilisateur d’utiliser de tels programmes pour trouver facilement des localisations similaires tout en pouvant préciser un périmètre de recherche.